When I started looking into the architecture of Large Language Models (LLMs),
I got confused when I encountered Retrieval Augmented Generation (RAG).
Both LLMs themselves and RAG use embeddings (a numerical vector
representation of a token) and through its shared terminology, I made the
wrong assumption that the embeddings in both are strongly related. It is
in fact much simpler, and while both use embeddings, they are unrelated to
each other.
Note: I'm still dipping my toes into the world of LLMs (and other generative
AI, like diffusion-models for image generation), so my posts might be
inaccurate. I welcome any feedback or comments on this.
Embeddings in a large language model
LLMs are trained to predict text given a certain input. The text that is
predicted are so-called tokens, small text snippets. These are then added to
the input text, and the LLM again predicts the next token, moving forward
until it predicted a special token that indicates the end of a text sequence.

Suppose the text at that point is the following:
Two roads diverged in a yellow wood,
and sorry I
You might know this as the start of "The Road Not Taken", a poem by Robert
Frost. If the LLM is trained with this poem, it might be able to predict the
next tokens. When I ran this as input through
Qwen3-VL 8B, one of the more recent
open-weights model released by the Qwen team at Alibaba Cloud, it was able to
generate parts of the poem further, but eventually strayed off course.
Two roads diverged in a yellow wood,
and sorry I couldn’t travel both
and be one traveler, long I stood.
and looked down one as far as I could
to where it bent in the undergrowth;
Then took the other, as just as fair,
and having perhaps a better claim,
because it was grassy and wanted wear;
though as for that the passing there
had worn them really about the same,
And both that morning equally lay
in leaves no step had trodden black.
And both … The question is — which way does he take? It’s not clear. He says “I took the other”,
but then says “the passing there had worn them really about the same”. So why did he choose one
over the other? Is it a matter of chance? Or is there something more symbolic going on?
Note: There is some randomness involved here, other iterations with the same
model and input did result in the poem being quoted correctly, followed by an
analysis of the poem.
While generating the output, the model generates one part of text at a time.
This part of text is called a token, and the LLM has a built-in tokenizer
that converts text into tokens, and tokens back into text. For the Qwen3
models, the Qwen tokenizer is used. If I understand its vocabulary correctly,
the text "couldn't travel" would be tokenized into:
[ "couldn", "'t", " ", "travel" ]
Different LLMs can use different tokenization methods, but there is a lot of
re-use here. Different LLM models can use the same tokenizer.
These tokens are converted into embeddings, which form the foundational
representation for use in LLMs. They are numerical vectors that represent
those text tokens. LLMs work with these numerical vectors: LLMs (and
AI in general) are software systems that perform heavy computational
operations, performing many matrix operations with each matrix being a
massive set of numbers. Well, text is represented as a huge matrix.
Embeddings are not just a simple index, but are pretrained values. These
values enable token mapping based on semantic similarity. When the training
material often combines "corona" and "COVID", then these two will have
embeddings that allow both terms to be seen as close to each other. But the
same is true if there is material combining "corona" and "beer". So the
embedding that represents "corona" (assuming it is a single token) would have
semantic understanding of both corona being a viral disease (related to
COVID-19) as well as an alcoholic beverage.
Unlike tokenizers, which can be reused across different LLM models, the
embeddings are unique to each model. Sure, within the same family (e.g. Qwen3)
there can be reuse as well, but it is much less common to see this re-use
across different families.
The phrase "Two roads" would consist of three tokens ("Two", " ", "roads"),
which are converted into a corresponding 4096-dimensional embedding vector
during processing. The dimension is fixed for a particular LLM:
Qwen3 8B for instance uses embeddings of 4096 numbers. So that start would be
a matrix with dimensions 3x4096. The entire text itself thus would be
represented by a very large matrix, with one dimension being this embedding
size (4096 in my case), the other dimension being the amount of tokens already
used as text (both input and generated output).
These matrices are then used as input within the LLM, which then starts doing
magic with them (well, not really magic, it's rather maths, multiplying the
matrix against other in-LLM stored matrices, iterating over multiple blocks of
matrix operations, etc.) to eventually output a (sequence of) embedding(s),
which is appended to the input matrix to re-iterate the entire process over
and over again.

The maximum amount of tokens that a model can handle is also predefined,
although there are methods to extend this. For Qwen3 8B, this is 32768
natively, and 131072 with an extension method called YaRN. So, for the native
implementation, that means the maximum text size would be represented as a
matrix of dimensions 32768x4096.
Retrieval Augmented Generation
LLMs are trained with a certain set of data, so once it is finished training,
it does not have the ability to learn more. To make it more useful, you want
the LLM to have access to recent insights. Nowadays, the hype is all about MCP
(Model Context Protocol), which is having LLMs trained to understand that they
have tools at their disposal, and know how to call these tools (well, in
reality, they are trained to generate output that the software which executes
the LLM detects, makes a tool output, and adds the outcome of that tool back
to the text already generated, allowing the LLM to continue).
Before MCP the world was (and still is) using Retrieval Augmented Generation
(RAG). The idea behind RAG is that, before the LLM responds to a user's query
(prompt) it also receives new information from external data sources. With
both the user query and information from the sources, the LLM is able to
generate more useful output.
When I looked at RAG, I noticed it using embeddings as well prior to the
actual retrieval, so I wrongfully thought that those are the same embeddings,
and that the outcome of the RAG would be an embedding matrix as well, that the
LLM then receives and further processes...

I was misled by documentation on RAGs indicated things like "the data to be
referenced is converted into LLM embeddings", and that the technology used for
RAG retrieval are vector databases specialized for embedding-based operations.
Many online resources also looked at RAG as a complete, singular solution with
multiple components. So I jumped into conclusion that these are the same
embeddings. But then, that would mean the RAG solution would be tailored to
the LLM being used, because other LLM models (like Llama3, or Mistral) use
different embedding vocabulary.
Instead, what RAG does, is take the same prompt, convert it into tokens and
embeddings (using its own tokenizer/embedding vocabulary) and then uses that
to perform a search operation against the data that is added to the RAG
database. This data (which is the recent insights or other documents you want
your LLM to know about) is also tokenized and converted into embeddings, but
it is not those embeddings that are brought back to the main LLM, but the
plain text outcome (or other media types that your LLM understands, such as
images).
Why does RAG then use embeddings? Wouldn't a simple search engine be
sufficient? Well, the RAG's primary advantage is its ability to locate
relevant information more effectively through embeddings. Thanks to the
embedding representation, the RAG can find information that is related to the
user query without relying on keyword matches. You could effectively replace
the RAG engine with a simple search - and many LLM-powered software
applications do support this. For instance,
Koboldcpp which I use to run LLM
locally, supports a simple DuckDuckGo-based websearch as well.

The use of embeddings for search operations (again, completely independent of
the LLM) allows for contextual understanding. When a user prompts for "What
are the ingredients for Corona", a simple keyword-based search operation might
incorrectly result in findings of COVID-19, whereas in this case the query is
about the Corona beer.
These improved search operations are often called "semantic search", as they
have a better understanding of the semantics and meanings of text (through the
embeddings), resulting in more contextually relevant insights.
When is it "RAG" and when semantic search
Retrieval Augmented Generation is the process of converting the user query,
performing a semantic search against the knowledge base, and appending the
best results (e.g. top-3 hits in the knowledge base) to the user input text.
This completed input text thus contains both the user query, as well as pieces
of insights obtained from the semantic search. The LLM uses this additional
information for generating better outcomes. This entire pipeline (retrieving
context, augmenting the prompt, and then generating output) is what defines
"RAG".
I personally see RAG technology-wise being very similar to a regular
search: replace the semantic search with a search engine (which underlyingly
could also use semantic search anyway) and the outcome is the same. The main
difference is that RAG is meant for finding exact truth, information snippets
tailored to bring context information accurately, whereas a search engine
based retrieval would rather bring snippets of data back.
In the market, RAG also focuses on the management of the semantic search (and
vector database), optimizing the data that is added to the knowledge base to
be LLM-friendly (shorter pieces of accurate data, rather than fully-indexed
complete pages which could easily overload the maximum size that an LLM can
handle). It prioritizes efficient data management and insights lifecycle
control.
For LLMs, it also provides a bit more nuance. A web search would be presented
to the LLM as "The following information can be useful to answer the
question", whereas RAG results would be presented as actual insights/context.
LLMs might be trained to deal differently with that distinction.
Understanding that the semantic search is independent of the LLM of course
makes much more sense. It allows companies or organizations to build up a
knowledge base and maintain this knowledge independent of the LLMs. Multiple
different LLMs can then use RAG to obtain the latest information from this
knowledge base - or you can just use the engine for semantic searches alone,
you do not need LLMs to get beneficial searches. Many popular web search
engines use semantic search underlyingly (i.e. when they index pages, they
also generate the embeddings from it and store those in their own vector
databases to improve search results).
When new embedding algorithms emerge that you want to use, you must
re-generate the embeddings for the entire knowledge base. But that will most
likely occur much, much less frequently than using new LLM models (given the
rapid evolution here).
Conclusion
RAG is a feature of the software that runs the LLM, allowing for retrieving
contextual information from a curated knowledge base. RAG's use of embeddings
is related to its semantic search, not to the same embeddings as those used by
the LLM. The contextual information is added to the user prompt as text, and
only then 'converted' into the embeddings used by the LLM itself.
Feedback? Comments? Don't hesitate to get in touch on
Mastodon.
Images are created in Inkscape, using icons from
Streamline
(GitHub), released under
the CC BY 4.0 license, indexed
at OpenSVG.






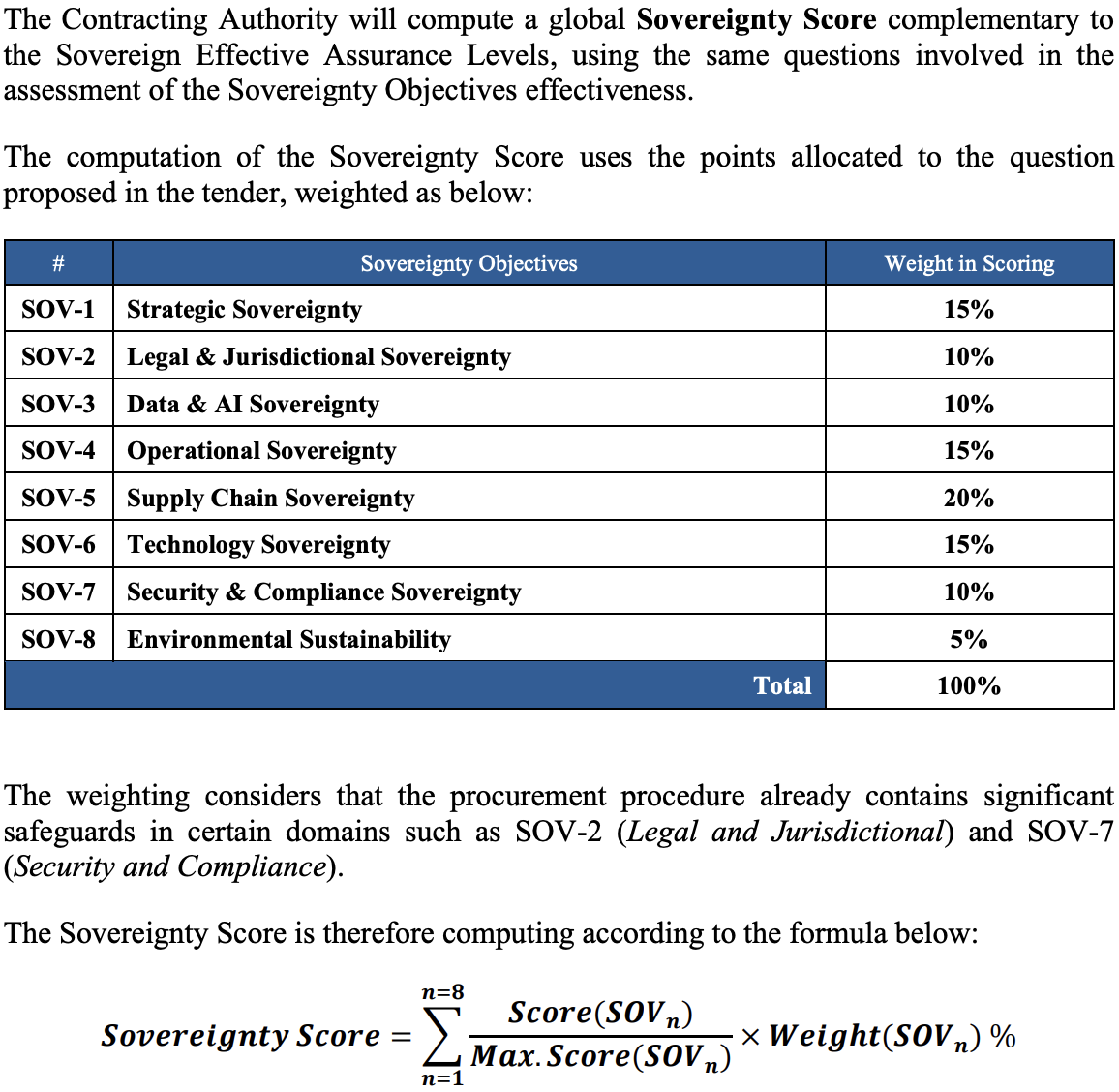 Screenshot of how the European Commission computes its composite sovereignty score. Technology Sovereignty (SOV-6), which covers open licensing, accounts for 15% of the total. Source:
Screenshot of how the European Commission computes its composite sovereignty score. Technology Sovereignty (SOV-6), which covers open licensing, accounts for 15% of the total. Source: 






























.jpg){kind=link}